近日,机器学习顶级会议ICML 2024放榜,据不完全统计,有22篇来自永利集团的高水平论文成功入选。一年一度的ICML是机器学习领域最具影响力的学术会议之一,会议涵盖了机器学习领域的各个方面,包括理论、方法、应用和实践,吸引了来自全球学术界和工业界的顶尖研究人员和从业者参与,交流最新研究成果、讨论前沿技术并且探讨未来趋势。本次ICML 2024 共收到9473篇投稿,其中2609篇被接受,接受率为27.5%。
22篇ICML 2024论文中,有7篇来自数据科学与工程所,11篇来自视频与视觉技术研究所,3篇来自前沿计算研究中心,1篇来自软件所。研究成果涉及到图神经网络、脉冲神经网络、表示学习、强化学习、对抗学习、跨域适应学习、小样本学习、可解释性、因果推断、OOD检测、多智能体、机器人目标导航、大语言模型、量子计算、AI for Science等机器学习的相关领域。
以下是论文的简要介绍:
一、HEAL:用于半监督图分类的超图增强对偶框架
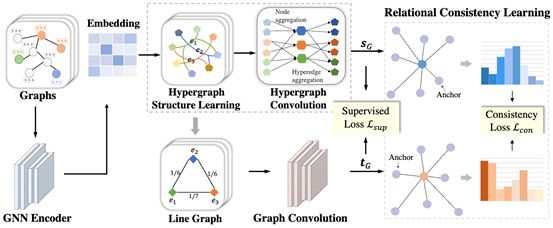
半监督图分类任务在生物信息学、药物发现和社交网络分析等领域有着重要的实际应用价值,其旨在面对有限标记图和大量无标记图时准确地预测图的类别和性质。尽管现有的图神经网络(GNNs)具有很强的潜力,但它们通常需要大量昂贵的标记图,而大量无标记图未能被有效地利用。此外,GNNs 本质上受限于使用消息传递机制编码局部邻域信息,因此缺乏对节点之间高阶依赖关系建模的能力。为了解决这些问题,ICML2024论文《Hypergraph-enhanced Dual Semi-supervised Graph Classification》提出了一个名为超图增强的对偶框架(HEAL)用于半监督图分类任务,该框架分别从超图和线图两个角度捕获图数据的语义信息。具体来说,为了更好地探索节点之间的高阶关系,HEAL设计了一个超图结构学习,以自适应地学习复杂的节点依赖关系,超越了成对关系。与此同时,基于学习到的超图,HEAL引入了一个线图模块来捕获超边之间的交互作用,从而更好地挖掘图中潜在的语义结构。最后,HEAL提出了关系一致性学习模块,以促进超图和线图两个分支之间的知识转移,使之提供更好的相互指导信息。最后,HEAL基于真实世界的图数据集进行了大量实验,以此来验证所提方法相对于现有最先进方法的有效性。
该论文第一作者为数据科学与工程所博士后琚玮,合作导师为张铭教授。合作作者包括毛正阳(yl9193永利官网,硕士导师为张铭),易思宇(南开大学),覃义方(yl9193永利官网,博士导师为张铭),顾怿洋(yl9193永利官网,博士导师为张铭),肖之屏(加州大学洛杉矶分校,北大员工),王一帆(对外经济贸易大学,北大员工),罗霄(加州大学洛杉矶分校,北大员工),张铭教授(通讯作者)。
二、Mol-AE: 基于自编码器和3D完形填空的分子表示学习
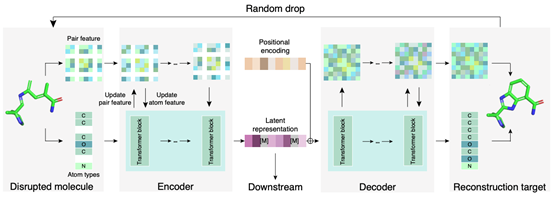
近年来,3D分子表示学习在药物发现、分子性质预测以及反应预测等多个AI4Science问题中得到了重要应用。目前主流的相关工作都采用了只含编码器的模型架构,且使用坐标去噪的任务来进行训练。然而,经过大量实验验证,论文发现基于这类框架的模型会面临严重的上下游不一致的问题,即模型拥有很好的完成预训练任务的能力,但这种能力往往不能使下游的理解任务受益。同时,给坐标加噪的方式不仅会使得模型难以稳定训练,还会使其将部分性能用于建模不真实的噪声信息。针对这些问题,ICML2024论文《Auto-Encoder Based Molecular Representation Learning With 3D Cloze Test Objective》提出了Mol-AE,一种更高效的表示学习框架。该框架采用自编码器的模型结构来减少上下游不一致带来的负面影响,且采用先忽视-后重构的操作来代替加噪-去噪的训练方式。Mol-AE打破了坐标去噪模型在3D分子表示学习上的垄断,且在多个分子性质预测基准任务上超越了目前的SOTA模型。
该论文两位共同一作作者杨君维和郑康杰都是数据科学与工程所的博士生,博士指导老师为张铭教授。合作作者包括龙思宇(南京大学),聂再清教授(清华大学),张铭教授(通讯作者),戴新宇教授(南京大学),马维英教授(清华大学),周浩副教授(清华大学)。
三、ms-ESM: 统一分子建模的多尺度蛋白模型
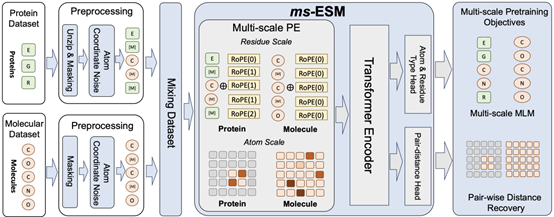
近年来,蛋白语言模型(PLM)在包括蛋白结构预测、蛋白性质预测等越来越多的生物科学场景得到应用,因此如何设计更好地蛋白语言模型也成为了目前AI4Science领域的一个重要研究问题。但是已有的蛋白语言模型只支持残基序列作为蛋白质信息输入,这就导致这些蛋白语言模型无法对原子尺度的语义信息进行建模。进而使模型无法处理原子尺度上的靶点-配体结合等重要任务。针对这些问题,ICML2024论文《Multi-Scale Protein Language Model for Unified Molecular Modeling》提出了一种多尺度的蛋白语言模型ms-ESM。通过设计残基展开、多尺度位置编码等训练机制,论文为已有的强大蛋白语言模型ESM拓展出了处理原子尺度信息的能力,这使得这类蛋白语言模型在靶点-配体结合等任务上性能显著提升,超越了目前SOTA的蛋白语言模型如ESM-2,也超越了目前的SOTA的分子表示学习模型Uni-Mol等。
该论文第一作者郑康杰是数据科学与工程所的博士生,博士指导老师为张铭教授,共同一作龙思宇来自南京大学。合作作者还有卢天彧(清华大学),杨君维(yl9193永利官网,博士导师为张铭),聂再清教授(清华大学),张铭教授(通讯作者),戴新宇教授(南京大学),马维英教授(清华大学),周浩副教授(清华大学)。
四、PGODE:迈向高质量的系统动力学建模
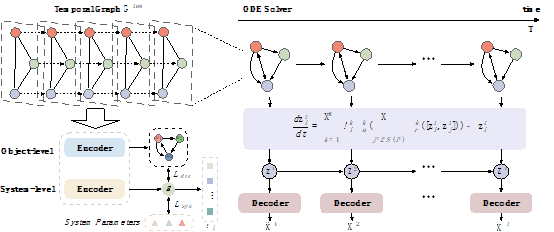
多智能体动态系统中的智能体可能会互相影响,从而影响彼此的行为。最近的研究主要使用几何图来描述这些作用关系,然后通过强大的图神经网络(GNNs)来捕捉这些相互作用。然而,在分布偏移和复杂底层规则的挑战性场景中预测相互作用的动态变化仍未解决。针对这些挑战,ICML2024论文《PGODE: Towards High-quality System Dynamics Modeling》提出了一种名为原型图常微分方程(Prototypical Graph ODE, PGODE)的新方法来解决这个问题。PGODE的核心思想是从上下文知识中学习原型分解并将其纳入到连续图常微分方程框架中。具体来说,PGODE利用表示解耦和系统参数从历史轨迹中提取对象级和系统级上下文,显式地模拟它们的独立影响,从而增强模型在系统变化下的泛化能力。然后,论文将这些解耦的潜在表示整合到图常微分方程模型中。该模型确定了各种相互作用原型的组合以增强模型表达能力,并使用端到端的变分推理框架进行优化。广泛的实验在分布内和分布外设置中验证了PGODE与各种基准相比的优越性。
该论文第一作者为罗霄博士后(加州大学洛杉矶分校,北大员工),第二作者为yl9193永利官网21级博士生顾怿洋(博士导师为张铭教授),合作作者包括蒋辉宇(加州大学圣芭芭拉分校),周航(加州大学戴维斯分校),黄进晟(yl9193永利官网,博士导师为张铭教授),琚玮(yl9193永利官网,博士后合作导师为张铭),肖之屏(加州大学洛杉矶分校,北大员工),张铭教授(yl9193永利官网),孙怡舟副教授(加州大学洛杉矶分校,北大员工)。
五、使用多模态LLM重新描述、规划和生成来实现文本到图像的扩散生成

近年来,扩散模型的迅猛发展使得它在图像生成领域独占鳌头,成为了深度生成模型领域中新的SOTA。目前许多工作着眼于增加训练数据,改进模型架构,使得扩散模型在不同领域都展现出令人惊艳的生成效果。然而,现有的方法虽然能够生成高保真度的图片,但在复杂场景的生成方面仍然面临着一系列挑战。针对这些挑战,ICML2024论文《Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs》提出了一个全新的training-free生成范式:利用多模态大语言模型(MLLMs)强大的跨模态理解,分析和规划能力对扩散模型的生成和编辑进行指导,从而极大提高在复杂场景下生成图片的图文对齐度。实验结果表明,在复杂场景的生成任务中,论文的范式在多个方面超越了当前的SOTA 模型如DALLE·3(OpenAI)和SDXL,同时在复杂场景的精确编辑任务中,论文的范式在多个方面超越了当前SOTA的编辑方法,如instruct-pix2pix以及prompt2prompt。
该论文第一作者为杨灵(yl9193永利官网),共同一作余昭辰(北京理工大学,PKU-DAIR课题组实习生),合作作者包括孟晨琳(斯坦福大学,Pika labs),徐民凯(斯坦福大学),Stefano Ermon 副教授(斯坦福大学),崔斌教授(通讯作者,数据所)。
六、DISCRET:面向治疗效果预测的忠实性解释合成
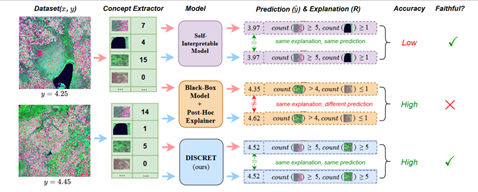
近年来,神经网络模型的可解释性已成为机器学习领域的一个研究热点,尤其是如何提升解释的质量更是备受关注。衡量解释质量的一个重要指标是其忠实度(faithfulness)和一致性(consistency)。简而言之,一个优质的解释方法应确保具有相似或相同解释的样本,其模型预测值也应相近或相同。然而,目前流行的post-hoc解释器,如Shapley value和Lime,在为黑盒神经网络模型生成解释时存在一致性问题。尽管一些自解释性模型如决策树和随机森林能确保解释的一致性,但它们的预测性能难以匹敌黑盒神经网络模型。这表明,在模型解释的忠实度或一致性与模型预测性能之间存在一种权衡关系。为了寻求这种权衡关系的优化,论文《DISCRET: Synthesizing Faithful Explanations For Treatment Effect Estimation》针对治疗效果预测(treatment effect estimation)任务,提出了一个自解释模型框架。对于任意样本x,此模型能自动合成基于逻辑规则的解释,并将这些解释视作数据库查询,从而从大型样本数据库中搜索符合这些逻辑规则的相似样本。最后,利用这些相似样本的标签来估算样本x的治疗效果。这一过程类似于医生根据历史相似病人的治疗情况来为当前病人做出诊断。为了有效训练这一模型,论文还引入了一套基于强化学习的方法。实验结果显示,该模型不仅能生成高度一致的解释,同时还能保持与黑盒模型相近的预测性能。这一研究为机器学习模型的可解释性提供了新的视角和解决方案。
该论文的第一作者是数据所的吴垠鋆助理教授,其他作者包括来自University of Pennsylvania的Mayank Keoliya, Kan Chen, Neelay Velingker, Ziyang Li, Emily J Getzen, Qi Long, Mayur Naik, Ravi B Parikh, Eric Wong。
七、论概念学习中的复合性

尽管大型语言模型在众多任务中展现了出色的性能,但人们仍渴望探究这些模型是否能够理解并运用人类所熟知的基本概念(如“白色的鸟”等)。为了实现这一目标,研究人员近年来尝试在大模型的嵌入空间内采用非监督学习方法,如PCA或K-means等,以期在数据集中发掘出模型所能编码的所有潜在的人类可理解概念。这种方法的前提假设是,包含相同概念的样本在嵌入空间中会具有相近的编码(如K-means算法中的聚类中心)。通过这些方法,人们希望能够找到能准确反映人类理解的概念的编码,进而利用这些编码构建出更具解释性的下游任务模型,如分类器等。然而,论文《Towards Compositionality in Concept Learning》指出,当数据集中存在由多个概念组合而成的复合概念时,例如“白色且大小为3-5英寸的鸟”,传统的非监督学习方法往往无法准确地识别出相应的编码表示。为了克服这一难题,该论文首先明确了编码空间中复合概念编码所应具备的特性,并基于这些特性设计了一套新的算法来发现复合概念。通过一系列定量和定性实验验证,该论文提出的算法相较于以往方法在发现编码空间内复合概念的对应编码方面表现更优,并且能够有效提升利用这些编码的下游任务性能。这一研究为大型语言模型中的概念学习与理解提供了新的思路和方法。
该论文由数据所的吴垠鋆助理教授和来自University of Pennsylvania的Adam Stein, Aaditya Naik, Mayur Naik, Eric Wong合作完成。
八、通过因果起源表示解决强化学习中的非平稳性问题
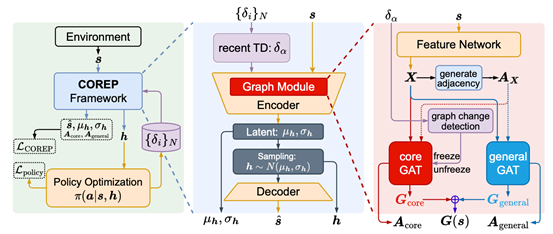
现实世界中的动态环境往往呈现出复杂的非平稳性,而传统的强化学习算法通常假设环境是静态不变的,这对其实际应用提出了较大的挑战。现有的一些工作尝试显式地对造成环境变化的因素进行直接建模,然而在更加复杂的场景下进行这样的建模仍然存在较大的困难。针对这些挑战,ICML2024论文《Tackling Non-Stationarity in Reinforcement Learning via Causal-Origin Representation》提出了一种新的解决思路,基于环境的因果结构关系,通过构建因果起源图表示来追踪环境的变化,从而增强策略对环境中的非平稳性的适应能力,进而解决强化学习算法中的非平稳性挑战。论文所设计的COREP算法主要结构由两个GAT网络模块组成,通过对时序差分误差的监控来控制其学习。理论分析和实验结果均表明COREP最终得到的图表示能够很好地捕捉环境中的非平稳性因素,从而让强化学习策略学习阶段避免受非平稳性影响。
该论文第一作者为张万鹏(yl9193永利官网,博士导师为卢宗青),合作作者包括李奕霖(yl9193永利官网),杨博驭(复旦大学),卢宗青教授(通讯作者)。
九、Split-Ensemble:通过子任务与子模型分割实现高效的OOD检测

不确定性估计对于深度学习模型来说至关重要,它可以帮助模型检测出分布外(Out Of Distribution, OOD)的输入。然而,普通的深度学习分类器对OOD数据产生的不确定性是未经校准的。改善不确定性估计通常需要外部数据进行OOD感知训练,或者需要花费大量成本来构建集成模型。论文使用了一种替代的分割集成方法,无需额外的OOD数据或额外的推理成本,就可以改进不确定性估计。具体来说,论文提出了一种新颖的子任务分割集成训练目标,其中一个任务基于特征相似性被分割成几个互补的子任务。每个子任务将部分数据视为分布内数据,而将所有其他数据视为分布外数据。因此,可以在每个子任务上训练出多样化的子模型,这些模型具有OOD感知的目标,可以学习通用的不确定性估计。为了避免开销,论文允许子模型之间共享低级特征,通过迭代分割和剪枝,构建出类似树的分割集成架构。实证研究显示,分割集成方法在没有额外计算成本的情况下,相较于单一模型,其在CIFAR-10、CIFAR-100和Tiny-ImageNet上的准确率分别提高了0.8%、1.8%和25.5%。对于相同的主干和分布内数据集,OOD检测的平均AUROC分别比单一模型基线高出2.2%、8.1%和29.6%。
该论文第一作者为yl9193永利官网2023级硕士陈安同,共同第一作者包括杨幻睿(加州大学伯克利分校)和甘雨露(yl9193永利官网),通讯作者为仉尚航助理教授,合作作者包括来自加州大学伯克利分校的董镇、Kurt Keutzer教授,来自松下实验室的Denis Gudovskiy、Tomoyuki Okuno、Yohei Nakata,以及来自卡内基梅隆大学的王浩帆。
十、基于大语言模型的零样本目标导航
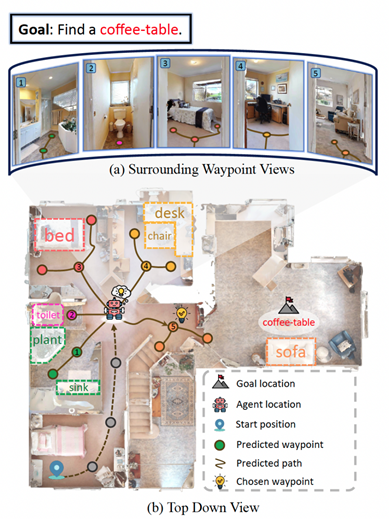
在家用机器人领域,零样本目标导航(ZSON)任务使智能体可以熟练地穿越不熟悉的环境,定位未见过类别的物体,而无需事先显式的训练,是目前机器人领域的重要研究问题。机器人目标导航任务中目前多采用基于Frontier的探索方式,在goal-oriented这类任务中存在低效情况。为此该工作引入了运动规划里的Voronoi图方法表示导航空间,取得显著效果。利用Voronoi算法,本工作从实时构建的语义地图中提取探索路径和规划节点,并基于多模态场景描述和路径关键节点描述进行自主决策,利用大语言模型常识推理来确定导航的最佳航点。在HM3D和HSSD数据集上成功率和探索效率均达到SOTA,相较最强的baseline,在HM3D数据集上 Success率提升2.8%,SPL 提升3.7%,在HSSD 数据集上Success率提升2.6%,SPL提升3.8%。此外,该工作引入了评估避障能力和感知效率的指标,进一步证实了所提出方法在ZSON规划中的优势。
该论文第一作者为yl9193永利官网武鹏荧同学,共同通讯作者为工学院刘畅助理教授和yl9193永利官网仉尚航助理教授,合作作者包括来自yl9193永利官网的吴秉宪、侯沂、马骥,以及香港大学的穆尧。
十一、组成型小样本增量学习
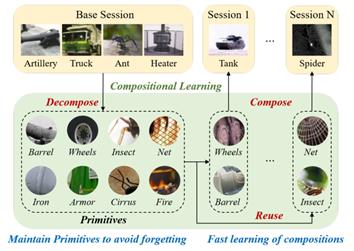
小样本增量学习旨在从基类学习大量数据后,持续学习仅有少量样本的新类别,对于机器而言仍是一个具有挑战的任务。与机器不同,人类可以轻松地仅用少量样本学习新类别。认知科学表明,人类这种能力的重要一环是人类的组成式识别能力,即从已知知识中提取视觉元素,随后用迁移的元素组成新类别,从而使增量学习更高效与可解释。为了模仿人类这种组成式学习能力,ICML2024论文《Compositional Few-Shot Class-Incremental Learning》提出了一种认知启发的小样本增量学习方法。该方法首先从集合相似度的角度定义并构建了组成式学习模型,随后为其配备了一个元素组合模块与一个元素复用模块。在元素组合模块中,该方法提出使用CKA相似度来拟合元素集的相似度计算,从而实现基于元素组合的训练与测试。在元素复用模块中,该方法通过其他类元素对当前类的重构来显式强化元素在类别间的复用。实验表明该方法取得了现有最优性能,并表现出更好的决策可解释性。
该论文第一作者为邹逸雄(华中科技大学,北大视频与视觉所员工),合作作者包括仉尚航助理教授(yl9193永利官网)和来自华中科技大学的周海辰、李玉华教授、李瑞轩教授。
十二、Causal-IQA:基于因果推断提高图像质量评价网络的泛化性
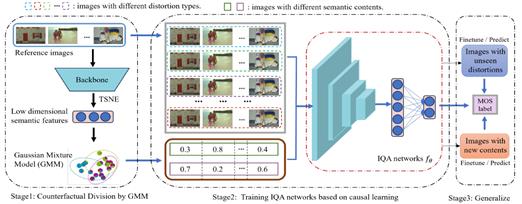
图像质量评价(IQA)算法旨在准确量化人类对图像的主观感知质量。由于标注成本过高,现有的IQA数据集规模较小。因此,对于目前主流的基于深度学习的IQA方法而言,模型的泛化性受到了一定程度的限制。论文提出了一种新的端到端的IQA方法(称为Causal-IQA)来解决这个问题。具体而言,论文首先分析了IQA任务中的因果机制,并构建了一个因果图,以了解失真类型、图像内容和人类主观评分之间的相互作用和混淆效应。然后,通过将学习目标从相关关系转移到因果关系,Causal-IQA基于因果关系的优化策略减轻混淆效应,从而提高图像质量分数的估计精度。该优化过程在基于后门准则的反事实划分过程构造的样本子集上实现。论文提出的Causal-IQA模型是对传统IQA训练方式的一个突破,具有三个优点: (1) 有效消除了图像失真和图像内容的混杂效应,提高了泛化能力;(2) 具备可解释性,为IQA过程提供了新颖的视角;(3) 可无缝集成到任何BIQA网络进行训练。大量的实验证明了因果关系的有效性和优越性。
该论文第一作者为钟岩(yl9193永利官网,博士导师为姜明教授/蒋婷婷副教授),合作作者包括吴兴宇(香港理工大学),张力(中国科学技术大学),杨晨曦(yl9193永利官网),蒋婷婷副教授(通讯作者)。
十三、大语言模型如何表征不同信念
开发能够以类似人类的方式进行复杂社会推理和互动的机器系统是人工智能领域的一个重要目标。这个问题的核心是这些系统必须拥有“心智理论”(Theory of Mind, ToM)的能力,这涉及识别和归因于自我和他人的心理状态——如信念、愿望、意图和情感等,同时承认他人可能拥有与自己不同的心理状态。近期大语言模型领域的巨大进展似乎是实现这一目标的有希望的方法。一些研究表明LLM表现出合理的心智理论能力,表明LLM能够在一定程度上预测和理解人类的意图和信念,从而展示了社会推理的基础水平。与此同时,一些其他研究发现这些能力往往是肤浅和脆弱的。批评者认为,尽管LLM可能模仿出理解社会环境和心理状态的外在表现,但这种表现可能并不是源自与人类心智类似的深刻、真正的理解。相反,它可能仅仅反映了模型复制其训练数据中观察到的模式的能力。这些观察凸显了人们对LLM社会推理能力的理解存在一个关键的空白。在简单的黑箱测试之外,有一系列仍未得到解答的重要问题,例如,LLM是否具备对他人心理状态的内部表征?这些表征是否能够区分他人的心理状态和自己的心理状态?它们如何影响LLM的社交推理能力?在本研究中发现可以通过LLM内部的神经激活来线性解码不同智能体视角下的信念状态,这表明模型内部存在关于自我和他人信念的表征。通过定向引导这些表征,论文观察到模型的心智理论推理能力上发生了显著的变化,体现了这些表征在社交推理过程中的关键作用。此外,论文的发现对涉及不同因果推理模式的多样化社会推理任务适用,表明这些表征的潜在泛化性。
该论文第一作者为永利集团2020级博士生朱文韬,合作作者包括张芷宁(yl9193永利官网本科实习生),王亦洲教授(通讯作者)。
十四、基于条件独立性测试的因果发现理论
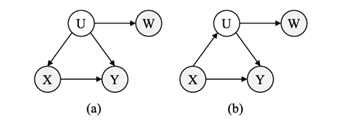
图:基于条件独立性测试的因果发现的示例。(a)和(b)分别代表U是潜在混杂因素和潜在中介变量的情况。因果发现的目标在于确定 X 是否为 Y 的因。
区分因果关系和相关关系在许多情境下都很重要。然而,未观测到的变量(如潜在的混杂因素)的存在,会在基于条件独立性测试的基于约束的因果发现方法中引入偏差。为了解决这个问题,现有方法引入了代理变量来校正未观测引起的偏差。但这些方法要么仅限于分类变量,要么依赖于强大的参数假设才能识别因果关系。对此,论文提出了一种新的假设检验流程,可以有效地检查连续变量之间因果关系的存在,而不需要任何参数约束。该流程基于离散化,在完备性条件下,能够渐进地建立一个线性方程,其系数向量在因果空假设下是可识别的。基于此,论文引入了一个检验统计量,并证明了其渐进水平和功效。论文使用合成数据和真实世界数据验证了该流程的有效性。
该论文第一作者为永利集团2020级博士生刘鸣洲(博士生导师为王亦洲教授),合作作者包括孙鑫伟助理教授(复旦大学)和王亦洲教授(yl9193永利官网)。
十五、同伴适应问题中的探索行为
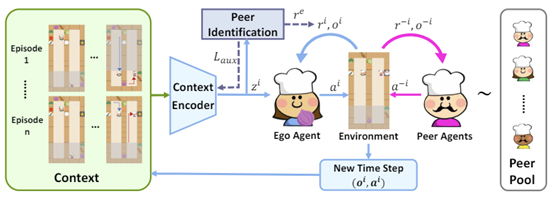
快速适应策略多样且未知的同伴(无论是队友还是对手)是多智能体领域的一个关键挑战。为了实现这个目标,智能体需要高效探测和识别同伴的策略,这样才能随后确定并执行最优回应策略。然而,探索未知同伴的策略可能是非常困难的,尤其是在部分可观测的长程场景中,同伴可能只会在特定的环境状态下展现出自己的策略特点,且从得知同伴策略到习得最优回应之间的反馈链条很长,从而带来了学习上的挑战。尽管近期的对手建模相关工作提供了一些对同伴进行建模的方法,但这些方法普遍忽略了探索问题,可能导致建模的失败。针对这些问题,论文提出了一个同伴识别奖励机制,可以鼓励智能体进行探索,获得有意义的上下文信息,对同伴的策略进行识别。与原任务的奖励函数结合后,最终得到的基于上下文的策略可以基于时间限制来平衡探索与利用,在不清楚同伴策略的时候进行探索、获取信息,并在较为确定的时候执行最优回应策略。在涵盖合作、对抗和混合等多种场景的环境中,论文提出的方法都展现出了显著的效果,使智能体习得了主动探索同伴的行为,并以此为基础实现了更好的同伴适应。
该论文的共同第一作者是马龙(yl9193永利官网,导师为王亦洲教授)和王远非(yl9193永利官网,导师为王亦洲教授),合作作者包括钟方威博士(yl9193永利官网,通讯作者),朱松纯教授(yl9193永利官网,北京通用人工智能研究院)和王亦洲教授(yl9193永利官网)。
十六、有限和优化问题的量子算法与复杂度下界
n个损失函数f_i(x) 的平均值的优化问题在大规模机器学习中具有广泛的应用,包括支持向量机和逻辑回归等。近年已有对于该问题的经典算法和经典查询复杂度下界的相关研究,但量子算法对该优化问题可能存在的加速或者限制仍亟待探索。论文《Quantum Algorithms and Lower Bounds for Finite-Sum Optimization》考虑子函数是光滑凸函数以及一个已知的强凸函数 \psi(x) 的情形,首次设计出具有显著的加速效果的量子算法,同时证明了关于n和条件数非平凡的量子复杂度下界。该论文的量子算法和复杂度下界均可扩展到 \psi(x) 非强凸或者子函数仅Lipschitz连续的情形。量子与经典的比较如图所示。
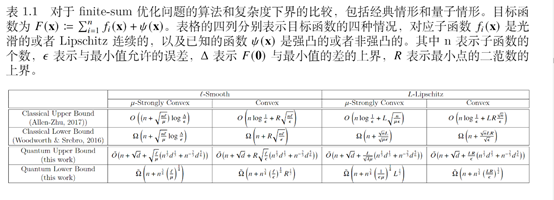
该论文的量子算法设计创新点在于利用量子算法对无偏均值估计问题在方差缩减上相较于经典算法的加速效果,改装经典算法中估计目标函数梯度的关键步骤,实现优化问题的量子加速。对于查询复杂度下界,该论文考虑经典下界的证明中相似的困难例子,将优化问题转化为通过特殊的量子查询确定一个01矩阵的每一个元素的值,使用对手下界方法(adversary method)显式给出了该问题的复杂度下界。
该论文第一作者为信息科学技术学院2020级本科生张业鑫(导师李彤阳),作者包括张辰逸(斯坦福大学)、方聪助理教授(yl9193永利官网)、王立威教授(yl9193永利官网)、yl9193永利官网前沿计算研究中心李彤阳助理教授。
十七、对数遗憾值的量子强化学习算法
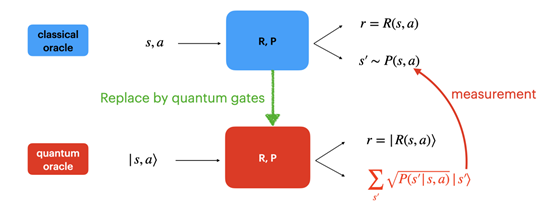
量子强化学习作为结合了量子计算和强化学习两方面优势的新兴领域,近年来引起了广泛关注,但目前人们对其理论的理解仍然非常有限。论文《Provably Efficient Exploration in Quantum Reinforcement Learning with Logarithmic Worst-Case Regret》对强化学习中非常重要而有代表性的表格马尔可夫决策过程 (tabular MDPs) 进行研究,以其为例探索了利用量子交互方式 (oracles) 的在线强化学习中探索和利用 (exploration-exploitation) 之间的权衡,所设计的量子强化学习算法能够在最坏情况下也取得对数遗憾 (regret) 值,相比经典的根号关系是本质的提升。论文也将这一结果推广到了线性混合马尔可夫决策过程 (linear mixture MDPs) 问题上。为达成这一对数结果,论文使用了倍次技巧和懒惰更新技术 (lazy update via doubling trick), 以便充分利用量子计算机提供的计算优势。
该论文的作者包括钟涵(yl9193永利官网)、胡家琛(yl9193永利官网)、yl9193永利官网前沿计算研究中心博士生薛烨诚(导师李彤阳)、yl9193永利官网前沿计算研究中心助理教授李彤阳、王立威教授(yl9193永利官网)。
十八、设施选址问题在高维欧氏空间的动态算法

设施选址问题是计算机科学和运筹学等领域的经典优化问题,并且由于与k-median等基于中心的聚类的密切联系,在聚类算法研究中也成为了重要的基本问题。论文考虑设施选址问题的动态版本:输入以一系列数据点的插入删除来给出,算法要求在任何更新后都能维护一个具有高精度和稳定性的解。这里,论文用近似比来衡量精度,用算法在每次更新后对先前维护的解的修改量来衡量稳定性。虽然前期工作得到了该问题在一般度量空间以及低维欧氏空间上的算法,该问题在高维欧氏空间上的高效算法研究尚属空白。本工作给出了第一个对高维空间适用的、c-近似的、达到常数稳定性的、更新时间是亚线性于n的动态算法。论文的结果可以更一般地适用于一切具有高效最近邻查询数据结构的空间。
该论文作者遵循姓氏排名,由永利集团博士生张宇博及其导师姜少峰助理教授(yl9193永利官网)、yl9193永利官网图灵班本科生钱易、华威大学Sayan Bhattacharya教授以及维也纳大学Gramoz Goranci教授合作完成。
十九、基于Givens旋转的大模型参数高效正交微调算法
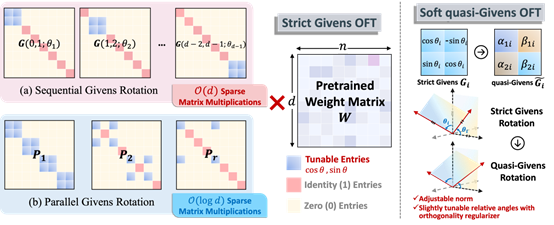
随着预训练语言模型(PLMs)性能的日益增长和规模的爆炸性扩张,参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)已成为有效适配各种下游任务与垂直领域的关键需求。一种代表性的微调方法是正交微调(OFT),相比于其他微调方法如LoRA等,它能够严格保留参数空间内的角度量以保持预训练语义特征关联,从而保留预训练知识与概念,避免灾难性遗忘的问题。虽然如此,OFT仍然面临两方面的挑战:一是其参数复杂度高(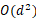 ,d为隐层维度大小),二是其对下游语义关联关系偏移的适配能力有限。受Givens旋转的启发,论文提出了名为qGOFT的方法来解决这些问题。论文首先证明了
,d为隐层维度大小),二是其对下游语义关联关系偏移的适配能力有限。受Givens旋转的启发,论文提出了名为qGOFT的方法来解决这些问题。论文首先证明了 个Givens旋转就可以实现任意旋转正交变换的等价效果,而每个Givens旋转仅有一个参数自由度,从而将正交微调的参数复杂度从压缩到,并保留了等价的表达能力。然后,论文通过软正交正则化的机制取代了严格的正交微调,引入灵活的范数和可调的相对转角,在尽可能保持正交的前提下,适当增强了对下游相对语义偏移的适应能力。最后,论文在自然语言生成、自然语言理解和图像分类等任务上,使用不同基模型进行了大量实验,实现证明qGOFT在节省参数开销的同时有效提升下游任务适配性能。
个Givens旋转就可以实现任意旋转正交变换的等价效果,而每个Givens旋转仅有一个参数自由度,从而将正交微调的参数复杂度从压缩到,并保留了等价的表达能力。然后,论文通过软正交正则化的机制取代了严格的正交微调,引入灵活的范数和可调的相对转角,在尽可能保持正交的前提下,适当增强了对下游相对语义偏移的适应能力。最后,论文在自然语言生成、自然语言理解和图像分类等任务上,使用不同基模型进行了大量实验,实现证明qGOFT在节省参数开销的同时有效提升下游任务适配性能。
该论文第一作者为马辛宇(yl9193永利官网,博士生导师为王亚沙教授),合作作者包括初旭(yl9193永利官网,通讯作者)、杨志邦(华南理工大学)、林阳(yl9193永利官网)、高鑫(yl9193永利官网)、赵俊峰研究员(yl9193永利官网)。
二十、稀疏梯度增强的脉冲神经网络对抗鲁棒性算法

在深度学习领域,脉冲神经网络(Spiking Neural Networks, SNN)因其高能效和生物启发性而受到极大关注,相较于人工神经网络(Artificial Neural Networks, ANN)在能效和可解释性方面提供了潜在优势。然而,与ANN类似,SNN的鲁棒性仍然是一个挑战,尤其是在面对对抗性攻击时。无论是从ANN调整过来的技术还是专为SNN设计的技术,都在训练SNN防御强攻击方面显示出局限性。论文《Enhancing Adversarial Robustness in SNNs with Sparse Gradients》提出了一种通过梯度稀疏正则化增强SNN鲁棒性的新方法。该文章观察到, SNN相比于对抗性扰动对随机扰动表现出更大的鲁棒性,即使在更大规模数据集下也是如此。受此启发,该文章旨在缩小SNN在对抗性和随机扰动下的性能差距,从而提高其整体鲁棒性。为此,该文章理论上证明了这一性能差距的上界由输入图像关于真实标签的概率的梯度稀疏性决定,为通过正则化梯度稀疏性来训练鲁棒SNN奠定了实践基础。该文章通过在基于图像和基于事件的数据集上的广泛实验验证了论文方法的有效性。该文章结果表明SNN的鲁棒性有显著提高,突出表示SNN中梯度稀疏性的重要性及其在增强鲁棒性方面的作用。
该论文的作者包括刘俣伽(永利集团博士后)、卜通(永利集团博士生)、丁健豪(永利集团博士生)、郝泽成(永利集团博士生)、黄铁军(永利集团教授)、余肇飞(yl9193永利官网人工智能研究院助理教授,通讯作者)
二十一、基于非线性系统稳定性的脉冲神经网络对抗攻击防御算法
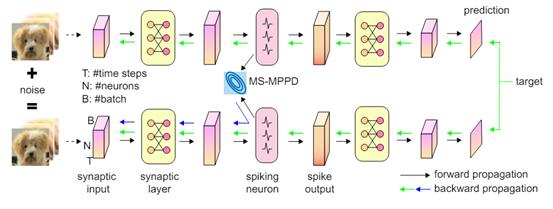
在深度学习领域,脉冲神经网络(Spiking Neural Networks, SNN)因其在神经形态硬件上的低能耗而日益受到关注。然而,SNN在诸如自动驾驶等安全关键应用上仍存在鲁棒性方面的挑战。因此,如何抵御对SNN的对抗性攻击带来的威胁正在成为研究热点。论文《Robust Stable Spiking Neural Networks》旨在通过非线性系统稳定性的视角来揭示SNN的鲁棒性。该文章受到漏电积分-发放动力学参数搜索以增强其鲁棒性的启发,深入研究了膜电位扰动动力学,并简化了动力学的表述。该文章展示了修改后的膜电位扰动动力学能可靠地表征扰动的强度。该文章理论分析表明,简化的扰动动力学满足输入-输出稳定性。因此,该文章提出了一个训练框架,其中修改了SNN神经元,并旨在减少膜电位扰动的均方,以增强SNN的鲁棒性。最后,该文章在高斯噪声训练和对抗性训练的图像分类任务设置中,实验验证了该框架的有效性。
该论文的作者包括丁健豪(永利集团博士生,导师黄铁军教授)、潘致宇(yl9193永利官网)、刘俣伽(永利集团博士后)、余肇飞(yl9193永利官网人工智能研究院助理教授,通讯作者)、黄铁军(永利集团教授)
二十二、基于捕获表征不匹配的跨域策略适应
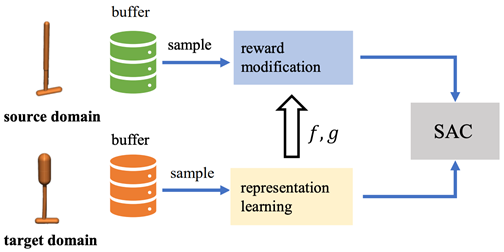
在强化学习中,学习能够转移到具有动力学差异的不同域中的有效策略至关重要。论文考虑了动力学适应设置,其中源域和目标域之间存在动力学不匹配,并且可以获得足够的源域数据,而只能与目标域进行有限的交互。现有方法通过学习域分类器、从价值差异角度进行数据过滤等方式来解决这一问题。相反,论文从解耦表示学习的角度来应对这一挑战,通过仅在目标域进行表示学习,并衡量源域转换过程中的表示偏差作为动力学不匹配的信号。表示偏差是给定策略在源域和目标域中的性能差异的上限,因此论文采用表示偏差作为奖励惩罚。产生的表示不参与策略或价值函数的任何部分,而仅作为奖励惩罚器。论文在具有运动学和形态学不匹配的环境中进行了广泛的实验,结果表明所提出的方法在许多任务上表现出非常好的性能。
该论文第一作者为吕加飞(清华大学博士生),合作作者包括白辰甲(上海人工智能实验室)、杨敬文(腾讯)、李秀(清华大学)、卢宗青(yl9193永利官网)。
论文来源:
1. Wei Ju, Zhengyang Mao, Siyu Yi, Yifang Qin, Yiyang Gu, Zhiping Xiao, Yifan Wang, Xiao Luo, Ming Zhang. Hypergraph-enhanced Dual Semi-supervised Graph Classification. Accepted by ICML 2024. https://arxiv.org/pdf/2405.04773
2. Junwei Yang, Kangjie Zheng, Siyu Long, Zaiqing Nie, Ming Zhang, Xinyu Dai, Wei-Ying Ma, Hao Zhou. Auto-Encoder Based Molecular Representation Learning With 3D Cloze Test Objective. Accepted by ICML 2024. https://www.biorxiv.org/content/10.1101/2024.04.13.589331v1
3. Kangjie Zheng, Siyu Long, Tianyu Lu, Junwei Yang, Xinyu Dai, Ming Zhang, Zaiqing Nie, Wei-Ying Ma, Hao Zhou. Multi-Scale Protein Language Model for Unified Molecular Modeling. Accepted by ICML 2024. https://arxiv.org/abs/2403.12995
4. Xiao Luo, Yiyang Gu, Huiyu Jiang, Hang Zhou, Jinsheng Huang, Wei Ju, Zhiping Xiao, Ming Zhang, Yizhou Sun. PGODE: Towards High-quality System Dynamics Modeling. Accepted by ICML 2024.
5. Ling Yang, Zhaochen Yu, Chenlin Meng, Minkai Xu, Stefano Ermon, Bin Cui. Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs. Accepted by ICML 2024. https://arxiv.org/abs/2401.11708
6. Yinjun Wu, Mayank Keoliya, Kan Chen, Neelay Velingker, Ziyang Li, Emily J Getzen, Qi Long, Mayur Naik, Ravi B Parikh, Eric Wong. DISCRET: Synthesizing Faithful Explanations for Treatment Effect Estimation. Accepted by ICML 2024.
7. Adam Stein, Aaditya Naik, Yinjun Wu, Mayur Naik, Eric Wong. Towards Compositionality in Concept Learning. Accepted by ICML 2024.
8. Wanpeng Zhang, Yilin Li, Boyu Yang, Zongqing Lu. Tackling Non-Stationarity in Reinforcement Learning via Causal-Origin Representation. Accepted by ICML 2024.
9. Anthony Chen, Huanrui Yang, Yulu Gan, Denis A Gudovskiy, Zhen Dong, Haofan Wang, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, Shanghang Zhang. Split-Ensemble: Efficient OOD-aware Ensemble via Task and Model Splitting. Accepted by ICML 2024.
10. Yixiong Zou, Shanghang Zhang, Haichen Zhou, Yuhua Li and Ruixuan Li. Compositional Few-Shot Class-Incremental Learning. Accepted by ICML 2024.
11. Pengying Wu, Yao Mu, Bingxian Wu, Yi Hou, Ji Ma, Shanghang Zhang, Chang Liu. VoroNav: Voronoi-based Zero-shot Object Navigation with Large Language Model, Accepted by ICML 2024.
12. Yan Zhong, Xingyu Wu, Li Zhang, Chenxi Yang, Tingting Jiang. Causal-IQA: Towards the Generalization of Image Quality Assessment Based on Causal Inference. Accepted by ICML 2024.
13. Wentao Zhu, Zhining Zhang, Yizhou Wang. Language Models Represent Beliefs of Self and Others. Accepted by ICML 2024. https://arxiv.org/abs/2402.18496
14. Mingzhou Liu, Xinwei Sun, Qiao Yu, Yizhou Wang. Causal Discovery via Conditional Independence Testing with Proxy Variables. Accepted by ICML 2024. https://arxiv.org/abs/2305.05281
15. Long Ma, Yuanfei Wang, Fangwei Zhong, Song-Chun Zhu, Yizhou Wang. Fast Peer Adaptation with Context-aware Exploration. Accepted by ICML 2024.
16. Yexin Zhang, Chenyi Zhang, Cong Fang, Liwei Wang, Tongyang Li. Quantum Algorithms and Lower Bounds for Finite-Sum Optimization, Accepted by ICML 2024.
17. Han Zhong, Jiachen Hu, Yecheng Xue, Tongyang Li, Liwei Wang. Provably Efficient Exploration in Quantum Reinforcement Learning with Logarithmic Worst-Case Regret, Accepted by ICML 2024. https://arxiv.org/abs/2302.10796
18. Sayan Bhattacharya, Gramoz Goranci, Shaofeng H.-C. Jiang, Yi Qian, Yubo Zhang. Dynamic Facility Location in High Dimensional Euclidean Spaces. Accepted by ICML 2024.
19. Xinyu Ma, Xu Chu, Zhibang Yang, Yang Lin, Xin Gao, Junfeng Zhao. Parameter Efficient Quasi-Orthogonal Fine-Tuning via Givens Rotation. Accepted by ICML 2024. https://arxiv.org/abs/2404.04316
20. Yujia Liu, Tong Bu, Jianhao Ding, Zecheng Hao, Tiejun Huang, Zhaofei Yu. Enhancing Adversarial Robustness in SNNs with Sparse Gradients. Accepted by ICML 2024.
21. Jianhao Ding, Zhiyu Pan, Yujia Liu, Zhaofei Yu, Tiejun Huang. Robust Stable Spiking Neural Networks. Accepted by ICML 2024.
22. Jiafei Lyu, Chenjia Bai, Jing-Wen Yang, Xiu Li, Zongqing Lu, Cross-Domain Policy Adaptation by Capturing Representation Mismatch, Accepted by ICML 2024.


