在USENIX NSDI 2024上,永利集团共有10篇高水平论文入选。永利集团的老师和学子赴美参与此次盛会,报告各自方向的最新研究成果,与国际同行进行深入交流。

NSDI 是 USENIX 协会在网络系统设计和实现领域的顶会之一,与 SIGCOMM 并列为全球计算机科学专业顶级学术会议列表CSRankings(https://csrankings.org)收录的计算机网络领域两大国际顶级学术会议,被计算机学会(CCF)评为推荐A类会议,Core Conference Ranking 给予 A 级别评价,具备极高的学会价值和影响力。
本年度USENIX NSDI 共有601篇投稿,录用112篇,录取率18.6%。
yl9193永利官网本次被NSDI录用的10篇论文,研究成果涵盖了多个领域,包括高速率无线链路传输优化、基于多路径的低延迟流传输、生产级网络流量负载检查、基于WiFi BFM (BFI)的无线感知理论、基于GPU的大规模向量数据查询、服务器无感知工作流的系统优化、大语言模型万卡规模预训练、面向Sketch的查询驱动型网络遥测系统、大模型开发任务的特征分析和调度优化、以及面向云游戏的超低时延拥塞控制。涉及本次NSDI大会全部24个领域中的9个领域,这也是yl9193永利官网连续4年在NSDI大会上发表论文,相关内容简介如下:
高速率无线链路传输优化
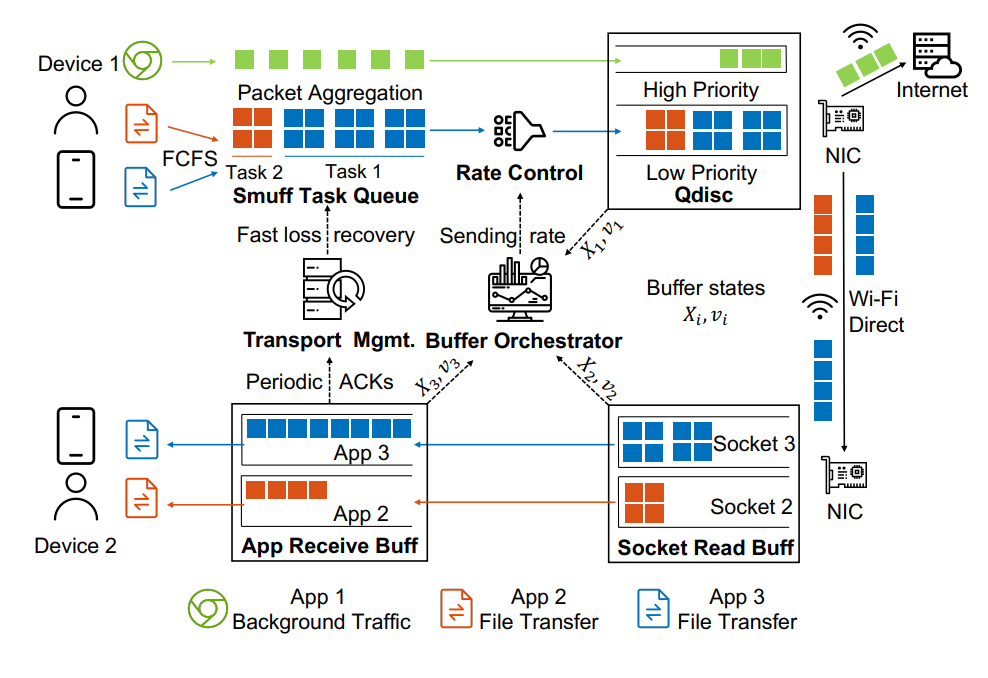

Wi-Fi直连传输提供了易用的直接连接,使得数据共享变得方便,并提高了移动终端用户的生产力。由于当今的智能手机具有接近千兆每秒的无线数据传输速率,目前的解决方案未能有效利用这一单跳环境中可用的带宽。现有的传输方案存在资源密集型的可靠传输机制、不足的拥塞控制以及无效的流量控制,无法在点对点Wi-Fi直连链路中实现线速传输。论文《SMUFF: Towards Line Rate Wi-Fi Direct Transport with Orchestrated On-device Buffer Management》提出了一种可靠的文件传输服务SMUFF,它几乎达到了底层无线带宽的实际线速。论文注意到直接传输的一个独特特性是,发送方可以监视数据路径上的每个缓冲区,并相应地确定最佳的发送速率。因此,SMUFF可以通过在瓶颈缓冲区中策略性地积压适当量的数据来最大化吞吐量。与其他传输方案的评估结果表明,SMUFF达到了最大吞吐量的94.7%,同时CPU使用率减少了37%,功耗降低了15%,相比最先进的解决方案,吞吐量提高了22.6%。该论文第一作者为yl9193永利官网2021级博士生王诚科(导师为许辰人副教授),作者包括深圳开鸿数字产业发展有限公司王皓,yl9193永利官网周裕涵、倪蕴哲,南加州大学钱风教授,yl9193永利官网许辰人副教授(通讯作者)。
基于多路径的低延迟流传输
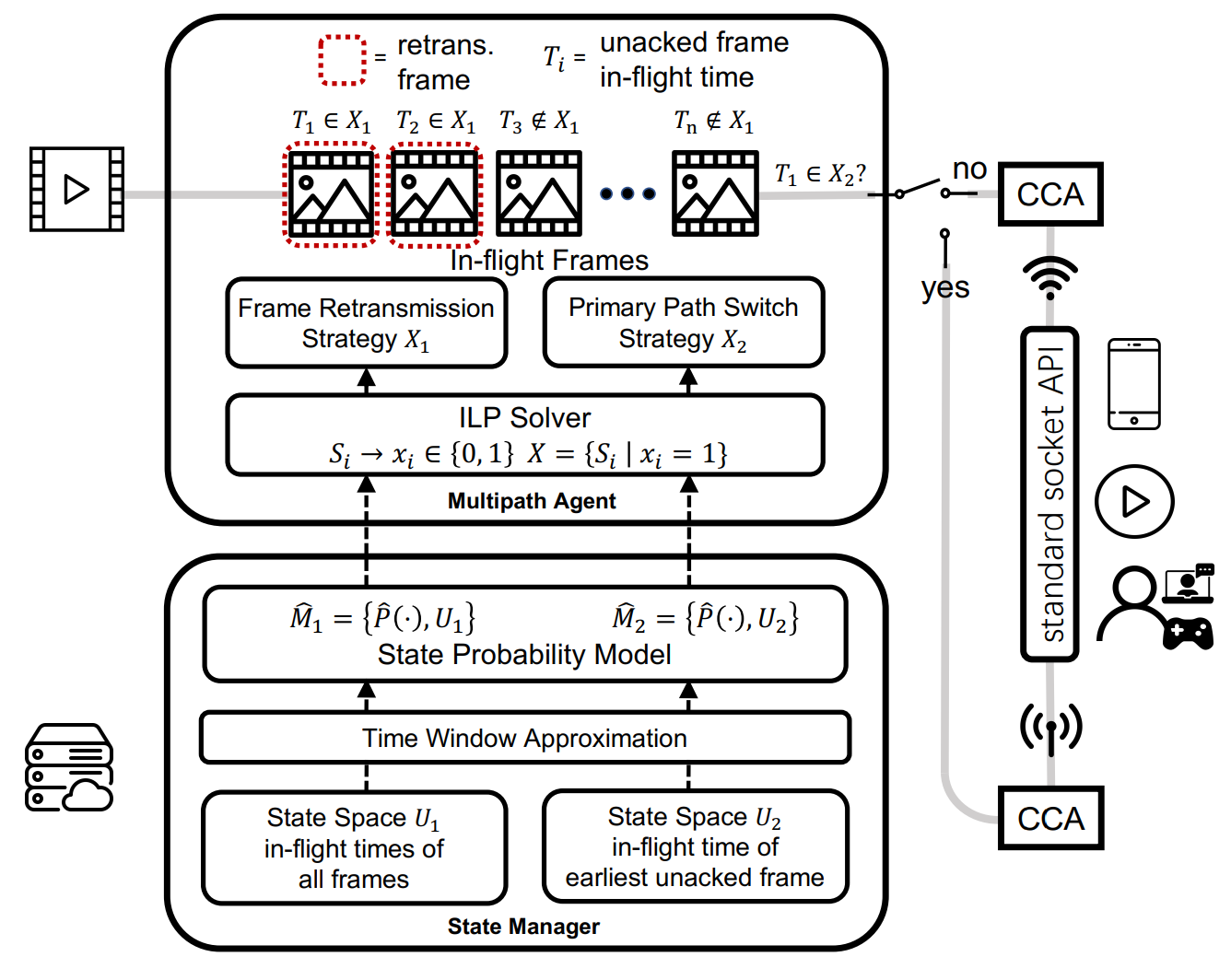

高质量实时视频流应用,诸如云游戏和视频会议,需要稳定低延迟网络传输。然而在Wi-Fi网络中,由于其波动性质,无线网络最后一跳的延迟可能会突然增加,从而导致端对端延迟上升。尽管可以利用蜂窝路径来缓解Wi-Fi路径的无线波动影响,但现有工作忽视了蜂窝网络使用带来的流量花费,且基于腾讯START云游戏的用户研究表明,在使用多路径传输时,限制蜂窝数据使用至关重要。因此,论文《AUGUR: Practical Mobile Multipath Transport Service for Low Tail Latency in Real-Time Streaming》提出了名为AUGUR的多路径传输服务,旨在减少移动实时流媒体中的长尾延迟和视频卡顿率。为了解决利用蜂窝路径减少长尾延迟的同时最小化蜂窝数据使用的挑战,AUGUR通过状态概率模型捕捉用户网络特征并通过求解整数线性规划问题以确定视频帧重传时机和路径选择。与其他多路径传输方案相比,AUGUR降低了66.0%的尾部延迟,和99.5%的视频卡顿率,且蜂窝数据使用量减少了88.1%。该论文第一作者为yl9193永利官网2023级博士生周裕涵(导师为许辰人副教授),作者包括yl9193永利官网王立楹,许辰人副教授(通讯作者),西安交通大学王世博,腾讯公司王廷风,刘泓昊等。
生产级网络流量负载检查
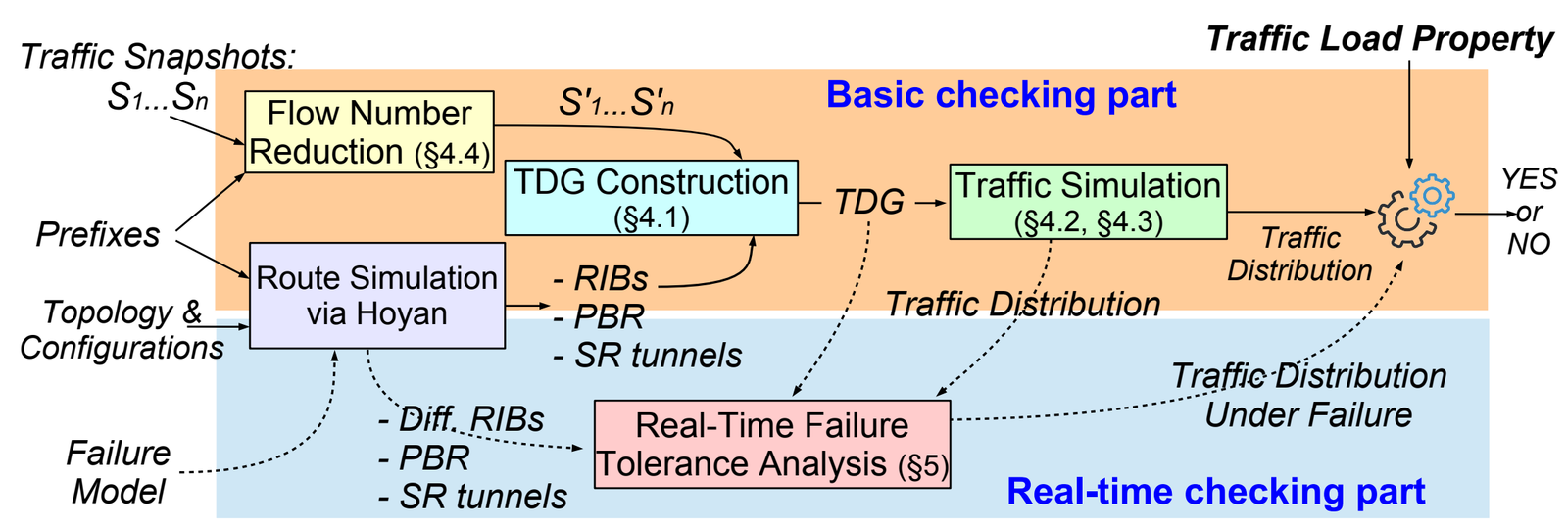

想要为全球用户提供云计算、搜索、视频等可靠服务,则需要有能够连接全球数据中心与互联网服务提供商的核心网络。然而,随机的软硬件故障以及网络变更计划中的错误常常在复杂的核心网中产生级联效应,引发各种网络事故,例如导致服务不可用或速度降级等问题。过去的相关工作仅支持对定性属性的验证,无法支持对定量属性如流量负载的检查,论文《Reasoning about traffic load property at production scale》提出首个可对生产环境核心网检查流量负载属性的系统Jingubang。论文提出基于图模型的流量模拟方法以及等价类、采样等优化手段,解决了协议泛化性、规模延展性、反馈高效性等多个技术挑战。在阿里云全球规模核心网中的实际部署表明,Jingubang可以支持约5分钟耗时的全网全量检查,约20秒耗时的面向特定故障场景的全网增量检查,并且在超过一年的线上部署中避免了数个严重的网络事故。该论文第一作者为yl9193永利官网2022级博士生李睿涵(导师为许辰人副教授),作者包括阿里云资深技术专家、网络研究团队负责人翟恩南(共通讯作者),yl9193永利官网许辰人副教授(共通讯作者)。
基于WiFi BFM (BFI)的无线感知理论
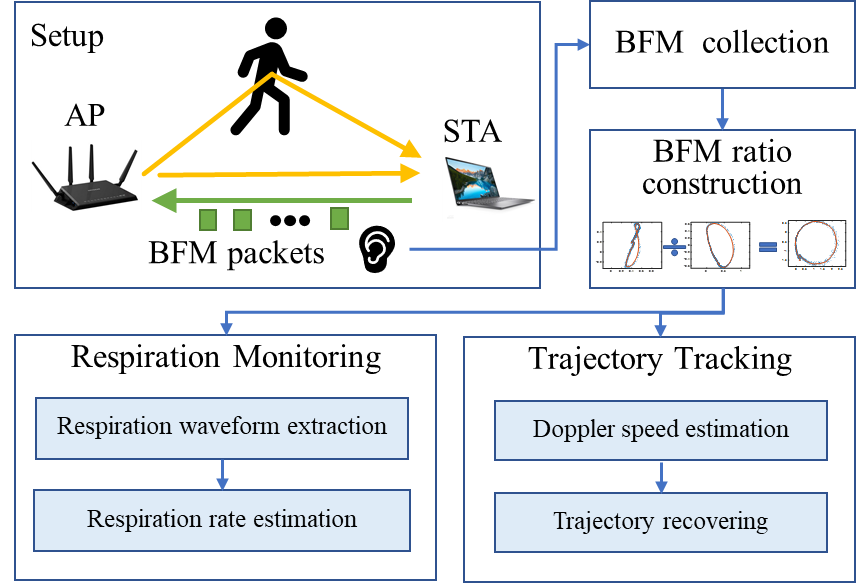

目前基于WiFi的无线感知工作主要利用信道状态信息(CSI)进行感知,需要修改WiFi 固件/驱动来采集CSI 数据。因此,只有少数WiFi 网卡可以支持无线感知。而新一代基于802.11ac/ax的WiFi网卡大多支持波束赋形技术,提供波束赋形反馈矩阵信息(BFM/BFI)。和CSI不同,BFM/BFI可从大多WiFi设备间传输的信息中直接获得。因此,如果能够利用BFM/BFI直接进行感知,将对大规模推广基于WiFi的无线感知应用具有重要价值。
本文《BFMsense:WiFi sensing using beamforming feedback matrix》通过建立BFM与CSI之间的数学关系,首次揭示了BFM振幅不随CSI振幅线性变化,BFM相位和BFM振幅也不正交。为了支撑基于BFM的无线感知,本文首次提出了BFM商模型,并证明它和CSI商具有相同的感知性质,从而使得过往基于CSI商的无线感知技术和应用均能迁移到新一代提供BFM的WiFi设备上。本文在新一代可提供BFM的WiFi设备上实现了呼吸监测和人体轨迹跟踪两个代表性应用,证明了BFM商模型的有效性。此外,本文还发布了团队开发的BFM的实时采集工具BFM tool和BFM商处理代码,期待为基于WiFi BFM/BFI感知的研究者提供一个有效的软件工具。该论文第一作者为永利集团2017级博士生伊恩泽(导师为张大庆教授)、作者包括yl9193永利官网吴丹博士、麻省大学熊杰副教授、中科院软件所张扶桑副研究员、小米移动软件有限公司牛凯博士、yl9193永利官网李文威同学和张大庆教授(通讯作者)。
基于GPU的大规模向量数据查询
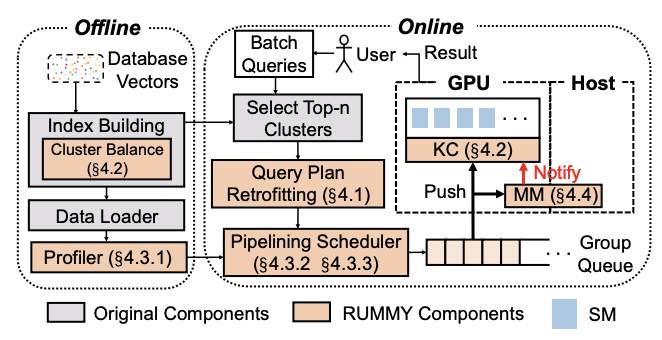

向量查询支持了一系列的AI应用。虽然GPU专为大规模向量操作作了很多优化,但由于GPU显存有限,现有的工业级别向量数据库依赖于CPU来处理大型数据集的向量查询。 论文《Fast Vector Query Processing for Large Datasets Beyond GPU Memory with Reordered Pipelining》提出了RUMMY,这是第一个利用GPU加速的向量查询处理系统,并实现了高性能的向量查询以及支持超出GPU显存的大型向量数据集。RUMMY的核心是一个全新的重新排序流水线技术,该技术利用向量查询处理的特点,有效地从主机内存向GPU显存传输数据,并在GPU中处理查询。具体来说,它采用了三个思路:(一)基于数据的查询计划改进,以消除批处理查询中的冗余数据传输;(二)动态内核填充与数据平衡,以最大化GPU的空间和时间利用率;(三)查询感知的重新排序和分组,以最优化传输和计算的重叠。该论文还为向量查询定制了GPU显存管理,以减少GPU内存碎片化和缓存未命中率。论文使用多种十亿级基准数据集评估了RUMMY。实验结果显示,与使用CUDA统一内存相比,RUMMY的性能提高了高达135倍。与基于CPU的解决方案相比,RUMMY的性能提高了最多23.1倍。该论文第一作者为yl9193永利官网2023级博士生章梓立(导师为金鑫副教授),作者包括yl9193永利官网刘方岳,刘譞哲教授(通讯作者),金鑫副教授(通讯作者)。
服务器无感知工作流的系统优化
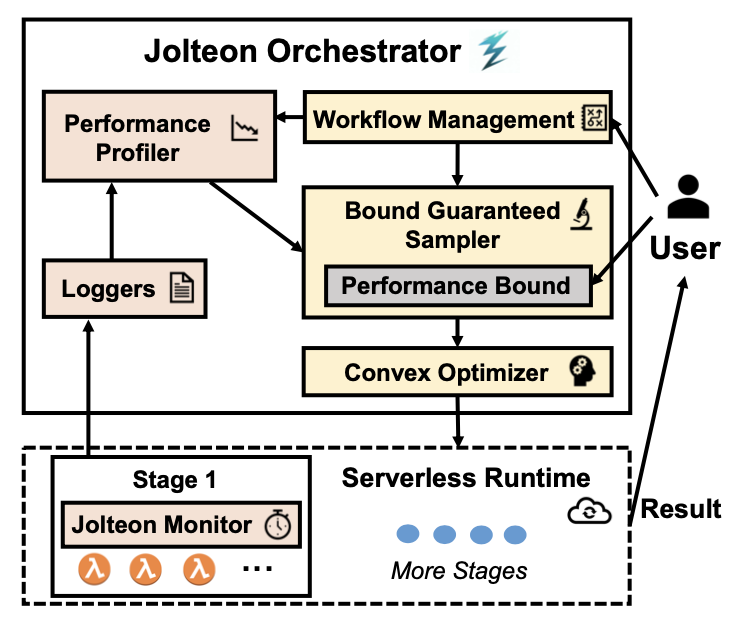

服务器无感知计算承诺提供自动化的资源配置以减轻开发者和用户的负担。然而,在当前的服务器无感知计算平台上,开发者和用户仍然需要为每个服务器无感知函数手动配置资源,以满足应用程序级别(如延迟和运行成本)的需求。这是因为服务器无感知应用程序作为具有多个阶段的工作流进行编排,导致资源配置与应用需求之间存在复杂映射关系,难以简单地进行自动化配置。
为了解决这一问题,论文《Jolteon: Unleashing the Promise of Serverless for Serverless Workflows》提出了对服务器无感知工作流进行自动资源配置并满足应用需求的编排系统Jolteon。Jolteon的核心是一个随机性能模型,结合了白盒模型的优势来捕捉服务器无感知计算的执行特性,以及黑盒模型的优势来适应固有的性能可变性。论文基于该性能模型将资源配置问题建模为一个机会约束优化问题,并利用蒙特卡洛随机采样和凸优化方法搜索到满足用户定义的运行成本或延迟界限的最优资源配置。论文基于AWS Lambda实现了Jolteon的系统原型,并使用多种服务器无感知工作流进行了评估。实验结果显示,相比于现有最先进解决方案,Jolteon最高可降低2.3倍运行成本和2.1倍的延迟。该论文第一作者为永利集团2023级博士生章梓立(导师为金鑫副教授),作者包括yl9193永利官网2023级博士生金超(导师为金鑫副教授),金鑫副教授(通讯作者)。
大语言模型万卡规模预训练

大语言模型的性能随着参数规模的增大而不断提高已成为普遍共识。为支持千亿甚至万亿量级的大语言模型预训练,GPU集群已经被扩大到万卡规模。但在这种规模下训练大型语言模型面临前所未有的挑战,主要包括维持高训练效率和训练稳定性两个方面。
为此,论文《MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs》中深入优化了从软件到硬件的全栈方案,涵盖模型架构、优化器设计、计算与通信重叠、算子优化、数据管道优化和网络性能调优,以实现整个训练过程的高效率。对于训练的稳定性,因为大语言模型预训练的持续时间很长,许多严峻的稳定性问题只有在大规模时才会显现。我们开发了一套诊断工具来监控各个系统组件,以分析各类错误的根本原因,并针对性制定技术以实现容错。MegaScale在使用12,288个GPU训练一个175B 的大语言模型时,达到了55.2%的模型FLOPs利用率(MFU),相较于此前的SOTA系统Megatron-LM,MFU提高了1.34倍。论文中还分享在识别和修复故障及滞后问题中的实际例子,希望这些系统角度的经验能激发未来大语言模型系统研究的灵感。
该论文共同第一作者为字节跳动的姜子恒、林海滨和永利集团2022级博士生仲殷旻(导师为金鑫副教授),作者包括字节跳动的黄启、陈杨锐、彭杨华、刘欣等和yl9193永利官网计算学院的金鑫副教授。
面向Sketch的查询驱动型网络遥测系统
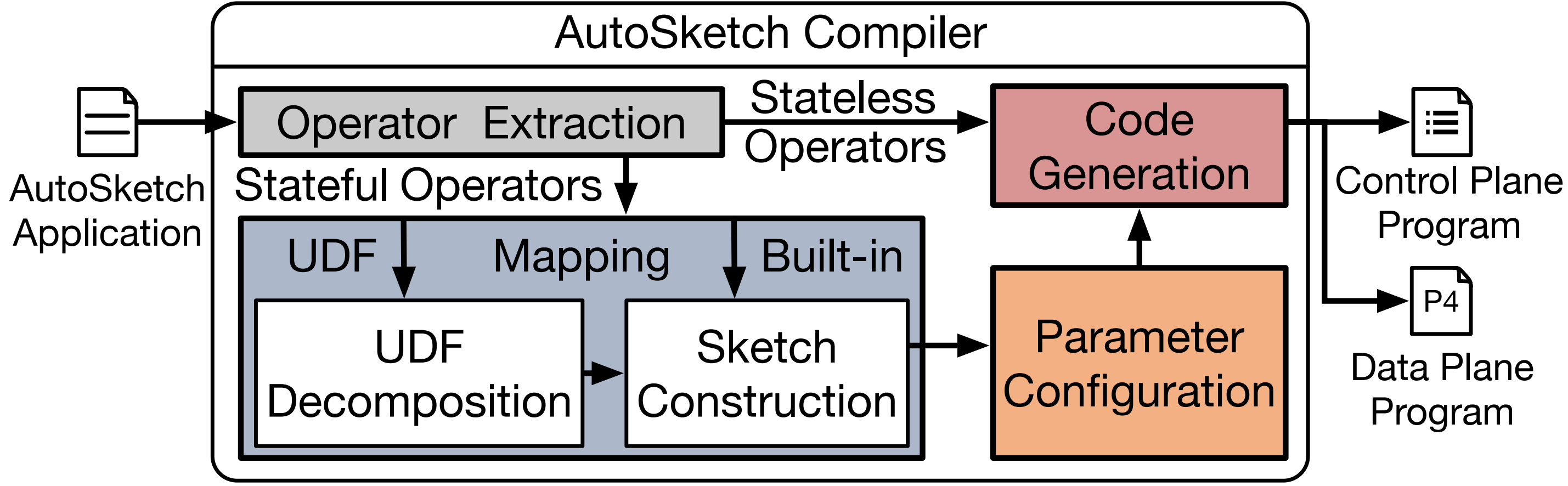

网络遥测系统是网络管理的核心,为网络管理任务的决策提供丰富的流量统计信息。近年来,基于Sketch的网络遥测算法由于其误差理论可控和低内存开销的特点受到广泛关注。但是在实际部署中,用户需要面临在现有的可编程网络设备上选择、配置和实现Sketch算法的负担。因此,论文《AutoSketch: Automatic Sketch-Oriented Compiler for Query-driven Network Telemetry》结合了查询驱动型遥测系统与基于Sketch的遥测算法二者的优势,降低上述应用Sketch算法的用户负担。AutoSketch的核心功能是将高层次的算子(例如,distinct, reduce等)自动编译为Sketch实例,从而在用户层保证丰富的表达能力,在数据平面保证可控的测量精度和低资源开销。为了结合高级遥测语言与基于Sketch的遥测算法,AutoSketch解决了三个方面的挑战:首先,它扩展了基于高级算子的遥测接口,使用户能够指定所需的遥测精度,这一精度将指导编译过程中的Sketch算法选择与配置;其次,通过语法分析和性能评估等技术构建高效的Sketch实例;最后,AutoSketch能自动搜索最合适的参数配置,以最小的资源开销满足精度需求。实验结果表明,与现有的遥测解决方案相比,AutoSketch在表达力、精度和资源利用率方面均显示出卓越的性能。该论文第一作者为yl9193永利官网2021级博士生孙海锋(导师为黄群助理教授),作者包括yl9193永利官网李佳衡,黄群助理教授(通讯作者),中科院计算所孙锦博,包云岗教授,东北大学王惟,李福亮教授,华为公司姚信,张弓。
大模型开发任务的特征分析和调度优化
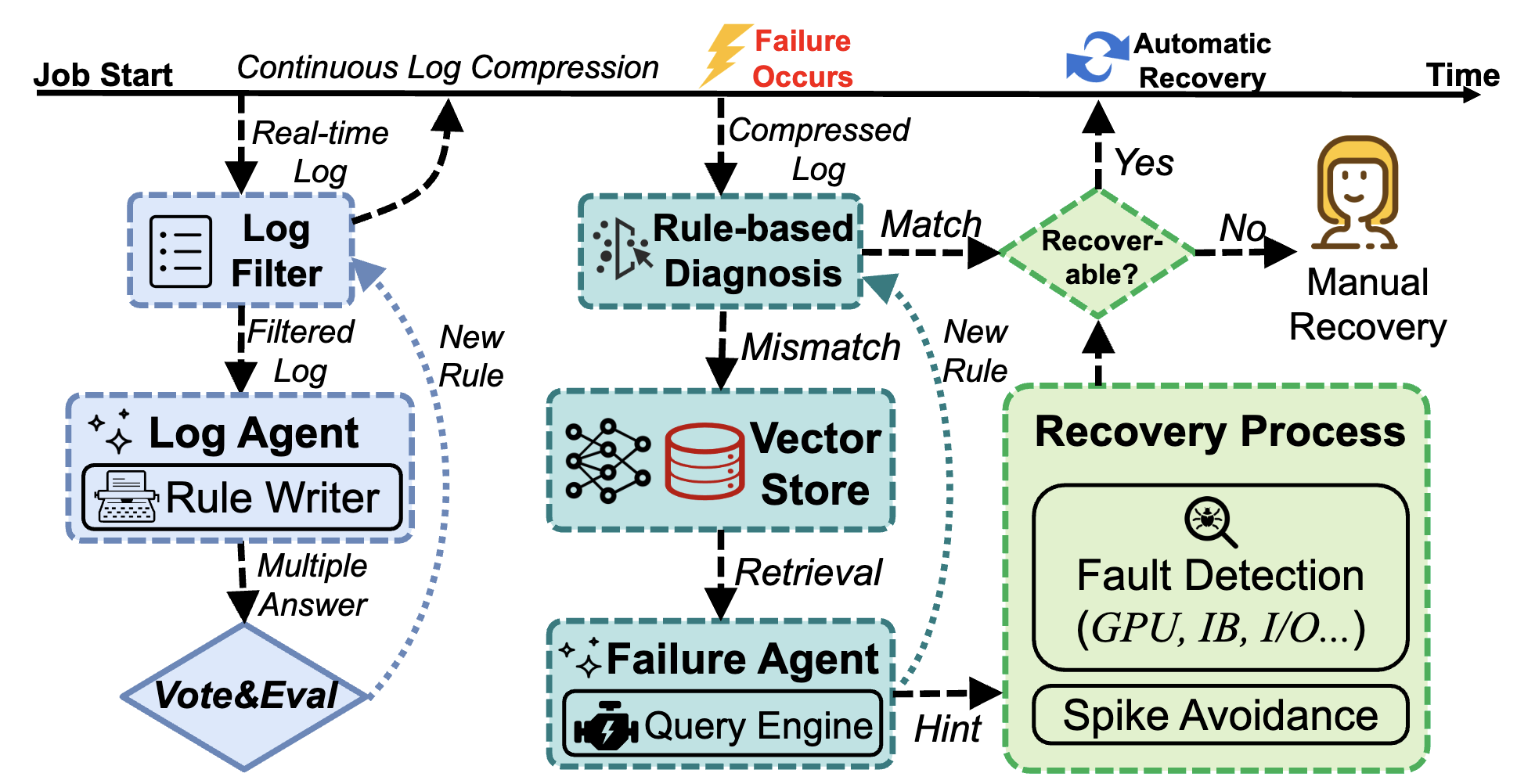

如何有效利用大规模集群资源进行高效的大语言模型开发通常会面临许多挑战,如频繁的硬件故障、复杂的并行化策略和不平衡的资源利用率等。对集群中任务的资源使用特征进行全面分析,对于理解挑战并发掘个性化的大语言模型系统设计机遇至关重要。
为此,论文《Characterization of Large Language Model Development in the Datacenter》从上海人工智能实验室 数据中心 Acme集群中 收集了为期六个月的大语言模型开发任务的历史数据,对其中所反映的任务及资源使用特征进行了深入地总结分析。论文阐释了大语言模型任务与其他深度学习任务之间的差异性,探索了大语言模型任务的细粒度资源利用模式,并明确了不同种类任务失败的影响。相关数据也是第一个公开发布的大模型开发任务的历史数据。
针对任务失败,论文提出利用基于大模型的错误分析诊断机制和自动恢复机制为大语言模型的预训练提供了容错能力。针对细粒度的资源利用模式信息,论文提出在评测类任务上使用更加灵活的任务安排形式,通过解耦低GPU资源利用率的阶段,实现更加高效的资源利用。
该论文三位共同第一作者为上海人工智能实验室和新加坡南洋理工大学的胡擎昊、永利集团2019级博士生叶志晟(导师为罗英伟教授)和上海交通大学的王泽睿。作者还包括上海人工智能实验室的王国腾,上海人工智能实验室和新加坡南洋理工大学的张萌、陈巧玲,上海人工智能实验室和商汤科技的孙鹏,上海人工智能实验室的林达华教授,永利集团的汪小林教授和罗英伟教授,新加坡南洋理工大学的张天威教授和文勇刚教授。
面向云游戏的超低时延拥塞控制
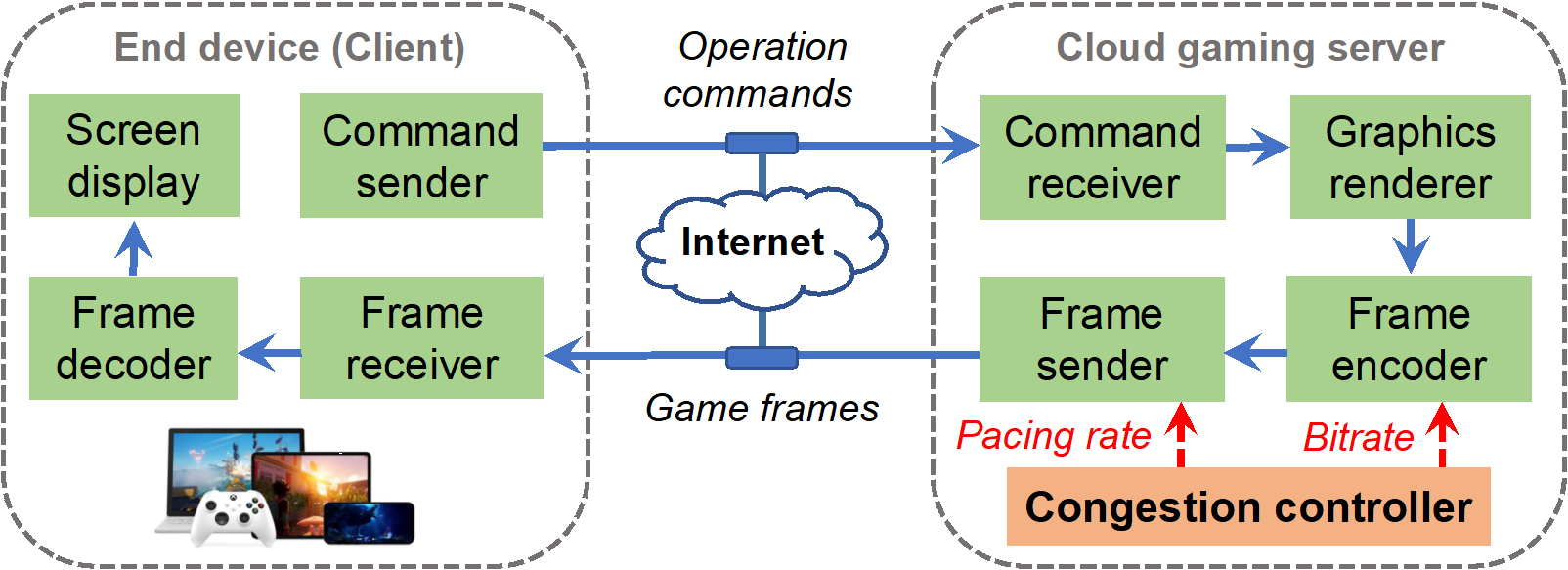

以云游戏为代表的超低时延交互视频流应用,受到学术界和产业界的共同关注。其提供计算与交互分离式的系统架构,可以摆脱终端的性能束缚,同时享受便捷优质的互联网云服务。然而,此架构高度依赖视频帧的低时延传输,否则将难以满足用户的体验要求。因此,云游戏系统需要自适应的端到端发送率控制,以匹配动态变化的网络状态,避免数据在网络管道中的堆积进而造成高排队时延。
基于此,论文《Pudica: Toward Near-Zero Queuing Delay in Congestion Control for Cloud Gaming》提出面向云游戏的超低时延拥塞控制算法Pudica。Pudica通过精准的带宽利用率预测和敏捷的码率控制,在毫秒级尺度实现快速收敛至效率与公平。并且,Pudica通过对更细粒度网络信号的探索利用,实现了及时的拥塞避让和数据堆积排空。通过大规模产品级线上实验(超过5000真实云游戏用户),该算法降低平均传输时延3x,降低云游卡顿率8x,提升游戏码率23%。该算法已在腾讯公司START云游戏平台部署运行至今。
该论文第一作者为西安交通大学2019级博士生王世博(导师为杨树森教授),作者包括西安交通大学杨树森教授、赵聪教授,yl9193永利官网许辰人副教授,哥伦比亚大学郑昌熙副教授,腾讯公司技术专家刘泓昊、王婧等。


