永利集团张杰课题组长期从事存储系统和新型非易失性内存的研究。张杰课题组在存内计算(PIM)、近存储计算(In-storage processing)、AI for storage和新型闪存架构研究取得重要突破,在国际计算机体系结构顶级会议HPCA发表论文4篇(会议总计录用75篇,录用率18%)。其中,本科实习生安昱达和唐云潇共同发表一作论文1篇,是yl9193永利官网本科生首次在国际计算机体系结构顶级会议发表论文。论文的简要介绍如下:
工作一 StreamPIM: Streaming Matrix Computation in Racetrack Memory
计算机领域中许多受到关注的新兴应用(如深度学习)属于内存敏感型应用,其性能受到内存墙问题的严重限制。构建在高存储密度、低能耗的赛道存储(RM)技术上的存内计算(PIM)系统有很大希望解决这一问题。然而,在现有RM存内计算方法中,内存存储单元与计算单元之间的松散耦合造成了很大的数据传输开销,严重限制了系统整体性能。为了解决这一问题,论文《StreamPIM: Streaming Matrix Computation in Racetrack Memory》(HPCA 2024)基于赛道存储,提出了一种新型的存内计算架构,即StreamPIM。StreamPIM采用物理学界的最新技术,基于赛道纳米线直接构建矩阵处理器,摆脱了对CMOS计算单元的依赖。同时基于赛道纳米线构建存内总线,进一步消除数据在存储单元和计算单元之间传输时的电磁转换开销。这两项技术使内存存储单元和计算单元紧密耦合。论文同时提出了一系列优化措施以提高存内计算的并行性,进一步提升整体性能。实验结果显示,与业内先进的赛道存储存内计算平台CORUSCANT相比,StreamPIM的性能提高了2.5倍,同时能耗减少到35%。
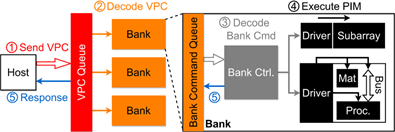
StreamPIM存内计算流程示例
该论文第一作者为元培学院2020级本科生安昱达和物理学院2019级本科生唐云潇(现已毕业),通讯作者为张杰助理教授,合作作者包括yl9193永利官网孙广宇副教授、罗昭初助理教授等。本文系yl9193永利官网本科生在国际计算机体系结构顶级会议发表的首篇论文。
工作二 BeaconGNN: Large-Scale GNN Acceleration with Out-of-Order Streaming In-Storage Computing
许多新兴应用依赖于对大规模存储数据进行大量不规则访问,而在传统的冯诺依曼架构中,这种情况会导致巨大的数据传输开销。计算型存储是解决这一问题的重要突破口,它将计算任务下放到基于闪存的固态硬盘,从而减少了数据搬移的需求。然而,随着闪存延迟降低至微秒级别,频繁的主机-存储通信开销以及低效的传统固态硬盘闪存控制方式成为该技术性能的瓶颈。
为解决这一问题,我们在论文《BeaconGNN: Large-Scale GNN Acceleration with Out-of-Order Streaming In-Storage Computing》(HPCA 2024)中,以大规模图神经网络计算为例,提出了多种面向超低延迟闪存内计算的优化技术。首先,我们将闪存地址信息等元数据融合到常规闪存数据中,以避免冗长的存储栈地址翻译,实现了盘内直接寻址。其次,我们扩展了闪存芯片和通道的计算能力,自动化了闪存后端的"数据搬移"、"闪存寻址"以及"闪存指令生成/路由"的过程,从而节省了闪存通道带宽,并绕过了闪存控制器的固件处理。实验证明,这两种优化技术显著提高了闪存数据吞吐量,相较于最先进的图神经网络计算存储设计,我们实现了11.6倍的性能增益,同时减少了76.5%的能耗。
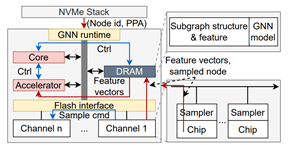
BeaconGNN系统架构
该论文第一作者为美国加州大学洛杉矶分校(UCLA)在读博士生王余越(本科毕业于yl9193永利官网信息科学技术学院),通讯作者为张杰助理教授和UCLA的Glenn Reinman教授。
工作三 LearnedFTL: A Learning-based Page-level FTL for Reducing Double Reads in Flash-based SSDs
随着3D NAND和NVMe技术的崛起,固态硬盘(SSD)的容量和性能大幅提升。然而,在SSD的闪存转换层(FTL)中存储所有地址映射表需要大量内存,在闪存中存储则会导致“双读”问题,严重影响读性能。为了解决这一问题,主流的需求驱动型FTL(DFTL、TPFTL等)利用工作负载的局部性缓存映射以减少双读现象的发生。然而,面对随机读取场景时,这些方案依然面临双读瓶颈。为了解决这一问题,论文《LearnedFTL: A Learning-based Page-level FTL for Reducing Double Reads in Flash-based SSDs》(HPCA 2024)提出了LearnedFTL,将学习索引与需求驱动型FTL结合,保证处理局部性工作负载能力的同时增强随机读性能。LearnedFTL以可调参数的分段线性模型为基础,建立就地更新线性模型摆脱对工作负载局部性的依赖,并通过虚拟物理地址表示法在保证并行性的同时满足学习索引的训练需求。同时,LearnedFTL提出了基于组的分配策略减少模型的空间开销,利用垃圾回收训练模型最小化训练开销,还通过一系列措施进一步提高模型准确性。实验表明,与现有的FTL方案相比,LearnedFTL的P99尾延迟可以减少5.3到12.2倍,随机读场景下,双读残留可以减少55%。这项研究为提高SSD性能,特别是在处理随机读取时,提供了一种创新解决方案。
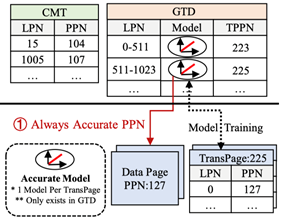
LearnedFTL系统架构
该论文由厦门大学毛波课题组、德州大学阿灵顿分校的江泓教授和张杰助理教授共同完成,通讯作者为毛波教授。
工作四 Midas Touch: Invalid-Data Assisted Reliability and Performance Boost for 3D High-Density Flash
计算机存储系统对密度与容量的需求持续增加,三星、美光等国外公司和国内长江存储近两年相继推出200层3D堆叠闪存芯片,并采用4比特每存储元的QLC技术。由于制程工艺的限制,3D QLC在可靠性与性能等方面面临着巨大挑战,故而其采用一种全新的编程方式,即基于WL粒度(4个物理页同时编程)的两步编程方式。厦门大学李乔老师团队在今年HotStorage论文中首次指出3D QLC的两步编程方式中,存在对无效数据页的编程,将其定义为无效编程问题(invalid programming)。针对该问题,本文首次提出系统的解决方案,利用无效页的存在实现有效页的高效编程,在不改变闪存芯片硬件的前提下,最小化对无效编程产生的能耗和性能损耗,并提升有效页的可靠性。论文提出了三个无效数据辅助策略来提升有效数据写入性能和可靠性。论文首先提出了一种对有效数据进行重新组织编程(Re-prog)的方案,避免对无效数据的精细编程操作,缩短编程的时间,提升了写入性能。其次,论文提出了非编程(Not-prog)方案,利用Wordline中存在的无效页,改变精细编程步骤中的数据,提升了其他有效页的可靠性。最后,论文基于最新的混合Flash,设计出了SLC和QLC区域之间的动态数据管理和自适应数据分配策略,减少了无效编程的发生。基于真实芯片和模拟器的评估表明,所提出的策略对3D QLC可靠性、性能和能耗均有较大的提升。

整体设计流程示例
该论文由厦门大学李乔课题组、香港城市大学的薛春教授、台湾大学的郭大维教授和张杰助理教授共同完成,通讯作者为李乔副教授。


